
Running Databricks jobs automatically after ETL completion
To ensure that Databricks workflows always operate on the most up-to-date data, Databricks notebooks can be configured to run automatically upon the completion of an ETL (Extract, Transform, Load) process. A master job (implemented as a Databricks notebook) streamlines the management of all dependent jobs and is automatically triggered once the ETL process finishes. This ensures that all downstream tasks are executed seamlessly using the latest data.
Steps to enable this feature
- Submit a request to the product support team by raising a task ticket. The support team configures the required settings and a job following the naming convention
ETL_SyncTrigger_<org_id>is created. - Link jobs by adding tasks within the workflow in Databricks (detailed in the following section). Once linked, all jobs connected to the ETLSyncTrigger<org_id> job will execute automatically after the next ETL process is completed.
Steps to link the notebook
- Navigate to the Databricks home page.
- Click Workflows. Once the support team has configured the settings,
ETL_SyncTrigger_<org_id>notebook will appear in the workflows list. - Click on the notebook name and open the notebook.
- Click Tasks.
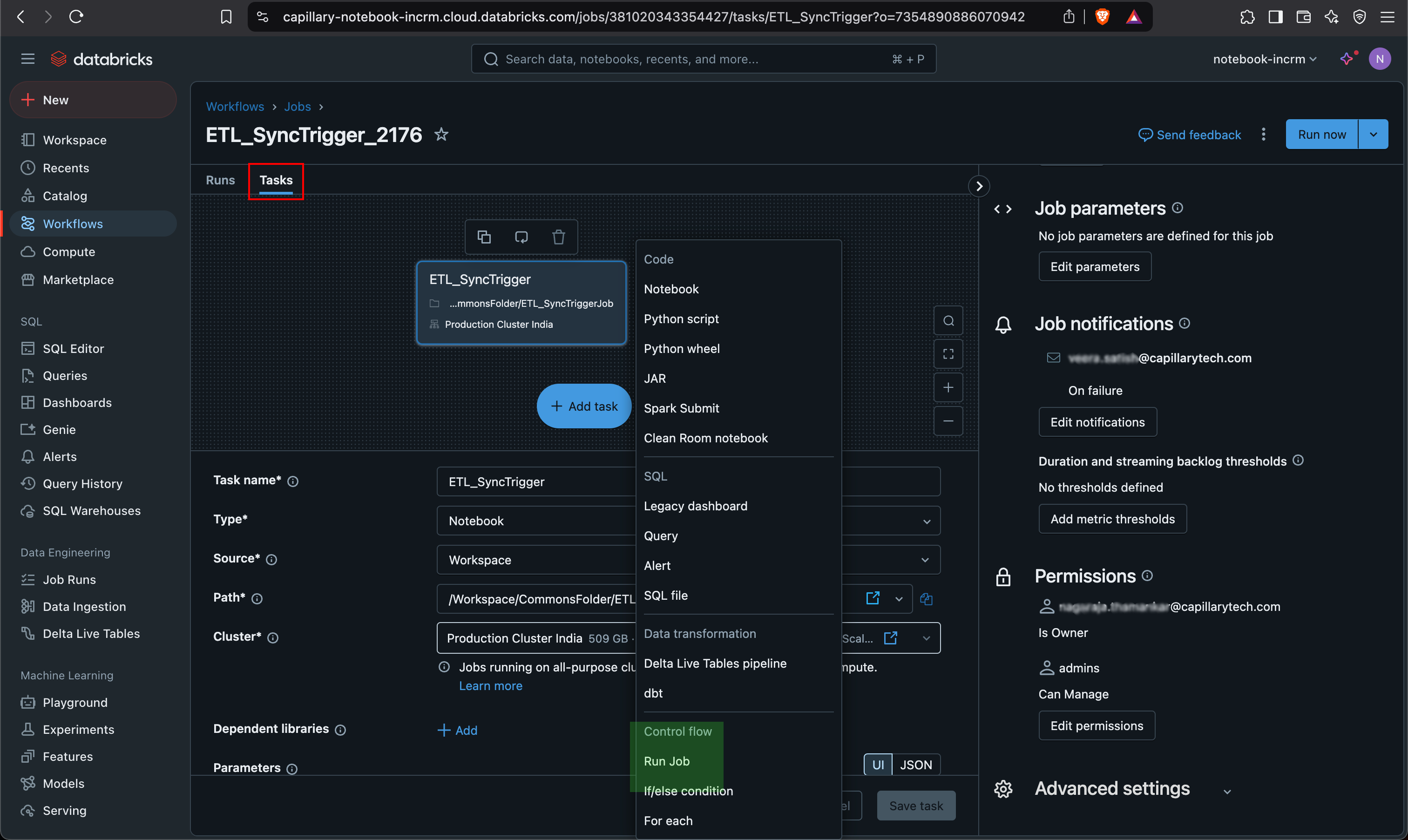
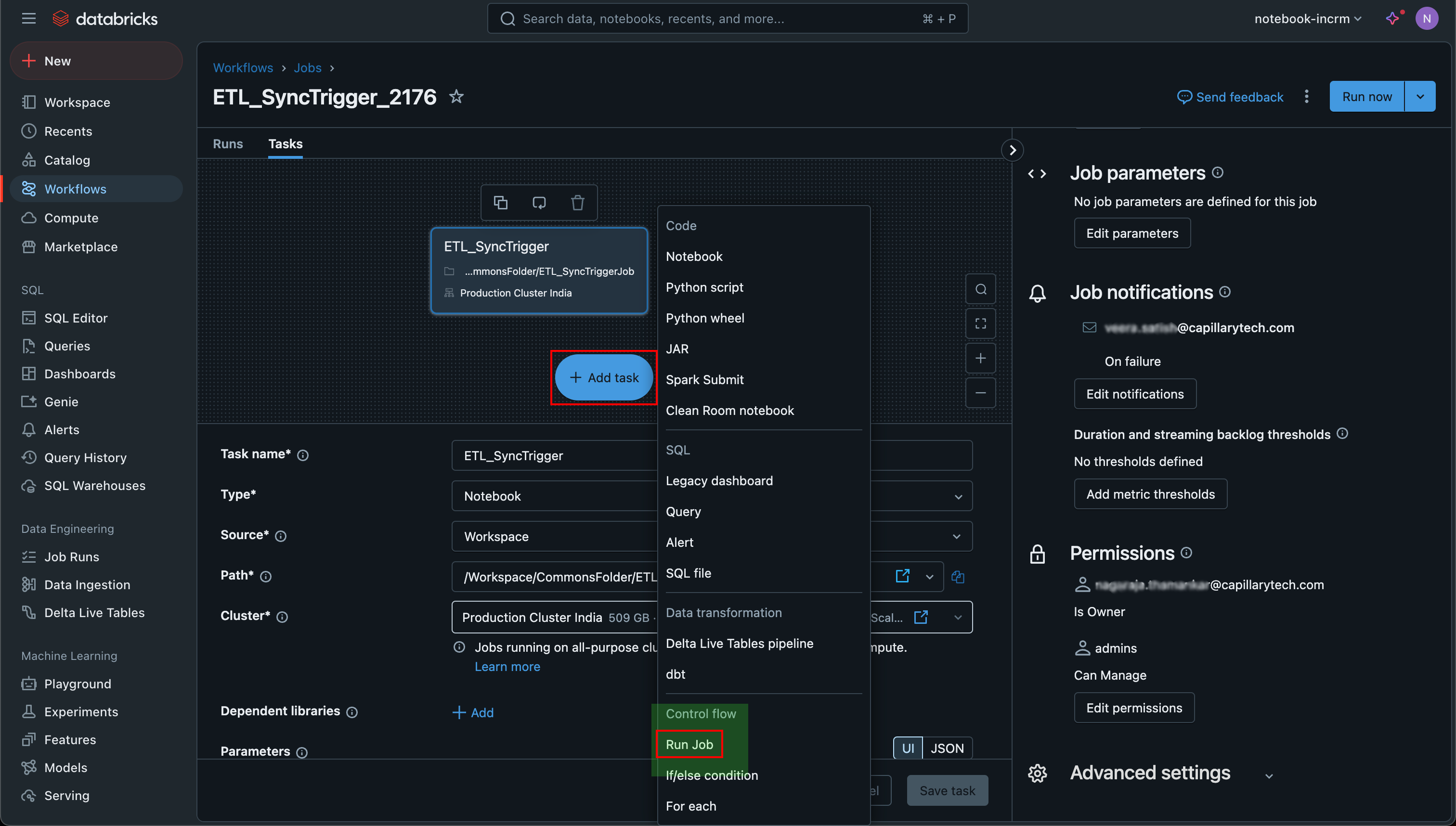
- Click + Add task > select Run Job.
Note: Make sure to click Run Job and not Notebook from the + Add task options.
All pre-configured jobs will be automatically populated.
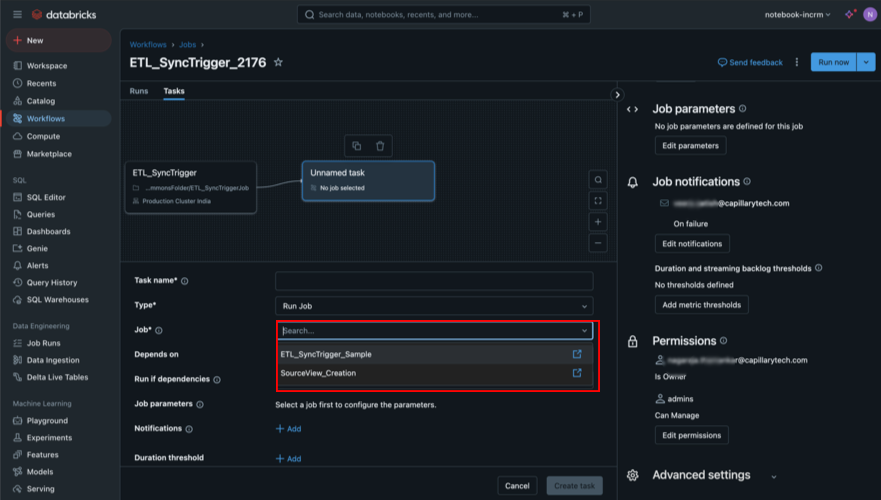
- Click Save task. The data will be synced upon completion of the next ETL.
Updated 18 days ago
Did this page help you?