
Data reconciliation template
This template helps to compare source data and the data in the Insight+ backend to identify the data that got missed during ingestion into Capillary.
The term source data refers to the data that is provided by the client and is considered the source of truth. The source data can be a .csv file or any other data format and contains events such as transactions or customer registrations.
The purpose of comparing source data with data ingested into the Capillary platform is to identify any missing events that may have failed to be ingested due to various reasons. The process of comparing the source data with the data in Capillary platform is known as data reconciliation and is important for ensuring accurate reporting and downstream events, particularly for loyalty customers.
Use case
Consider that on January 1st, 2022, there were 100 transaction events that were expected to be captured in the Capillary platform. However, due to certain issues or errors, only 90 events were successfully recorded in the platform, resulting in 10 missing events. These 10 missing events need to be identified and ingested into the platform.
With data reconciliation dataflow, you can compare the source data with the transactions in Insights+ backend and identify the missing data.
Configuring data reconciliation dataflow
To configure data reconciliation dataflow, perform the below steps/actions:
- In the Connect to source Block, enter the source server details where the source data is present and the location for saving the processed file. See Connect to source.
- In the Map fields for reconciliation block, map the source data fields to the CDP fields to initiate comparison and identify missing data. See Map fields for reconciliation.
- In the Trigger frequency block, set the trigger frequency. See Trigger frequency.
Map fields for reconciliation
In this section, you need to map the fields in the source data to the fields in the Capillary platform.
At present, the following transaction types of data can be compared with the Capillary platform.
- Regular transaction line items - To compare and identify missing regular transactions in the Capillary platform.
Map multiple fields to identify the unique transaction
If a transaction contains multiple line items with the same bill number but with different codes, and if you map only the bill number, when the system compares the source data with the data in the platform, it matches only the bill number and considers the transaction as already available in the platform.
If you map the bill number and other fields such as store code, year, bill date, rate etc, the system matches properly and identifies the missing transaction accordingly.
See the below image for an example of a transaction with the same bill number repeated multiple times but one among those appears against a different store code. In this case, if you map only the bill number, the system matches only the bill number and if a transaction with the respective bill number is available in the platform, after processing, it marks all transactions with that bill number as 1 (data already available in the system/not missing data).
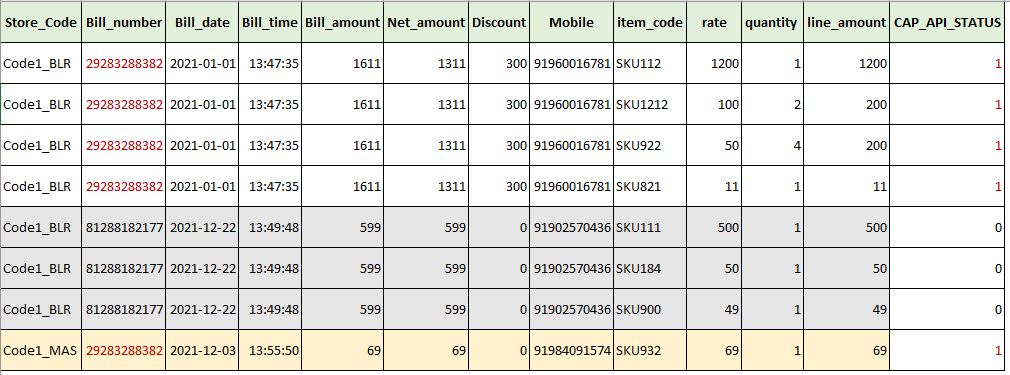
- Return transaction line items - To compare and identify missing return transactions in the Capillary platform. Similar to regular transaction line items, it is recommended to map multiples to identify the unique transaction.
- Customer - To compare and identify missing customer data in the Capillary platform.
- Product - To compare and identify missing product data in the Capillary platform.
- To map the field names, in the Transformation text box, enter the Capillary data field name against the corresponding source data field name (API field). For example, if the source data field name for the field that contains billing data information is Billing data, in the Transformation text box, enter the Capillary data field name where you have the same information.
- If you want to map the date fields, from the Date format drop-down, select the desired date format.
- In the From year field, enter the year from which you want to compare the data.
By default, it will compare source data with the platform data from the previous year to the present date.
If you enter a year, for example, 2016, it will compare source data with platform data from 2016 up to the current year. This option is available to speed up the comparison process. - In the Reconciliation Results Directory field, enter the directory where you need to save the processed data. In the processed file. If the URL is /APAC2Cluster/EUConnect, enter only the path APAC2Cluster/EUConnect in the Reconciliation Results Directory field. You can use this file to ingest the missing data to the Capillary platform.
In the output file, the application creates a CAP_API_STATUS column and in the column, the missing data is marked as 0 and the existing data is marked as 1.

Ingestion of the missing data
To ingest the missing data, perform the following
- Use the respective data flow template and in the connect to source, enter the Reconciliation Results Directory path in the Source Directory field. For example, if you want to add a missing transaction, enter the output file path of the Data reconciliation template in the source directory of the transaction add template.
- In the filter header field, enter the heading CAP_API_STATUS. This is the status column header in the processed file of the reconciliation dataflow.
- In the Filter-Data, define the Filter Condition as
${header_value:equals(0)}. This enables the template to ingest the rows that are marked as missing (0).
NOTEThe insights+ backend data has a lag of one day. ETL (Extract, Transform, and Load) runs only once every night (according to org time zone).
If you are running reconciliation dataflow on daily basis, make sure that you schedule the trigger with a gap of 12-24 hours after the ETL completion. Triggering the dataflow before the ETL completion can result in the system condidering the new data as missing data and ingessting it.
Updated 5 months ago