
Databricks job trigger template
The data bricks job trigger template allows you to trigger a data bricks notebook job that is already created. This template can be used to validate a set of records and further process the records that meet the validation requirements. The validation rules are defined in the Databricks notebook.
Use case
A brand wants to ensure the accuracy and integrity of the data before processing them further. They decide to implement batch feed validations using Databricks.
The brand's data engineering team develops validation rules using Databricks. These rules include checks for data completeness, consistency, and accuracy. For example, they may check if each order contains valid customer information, product details, and payment information.
Further, the brand can use the Connect+ template to trigger the Databricks notebook at regular intervals.
Configuring databricks job trigger template
To configure databricks job trigger dataflow, perform the below steps/actions:
-
In the Connect-to-source section Block enter the source server details where the source
data is present and the location for saving the processed file. See Connect to source. -
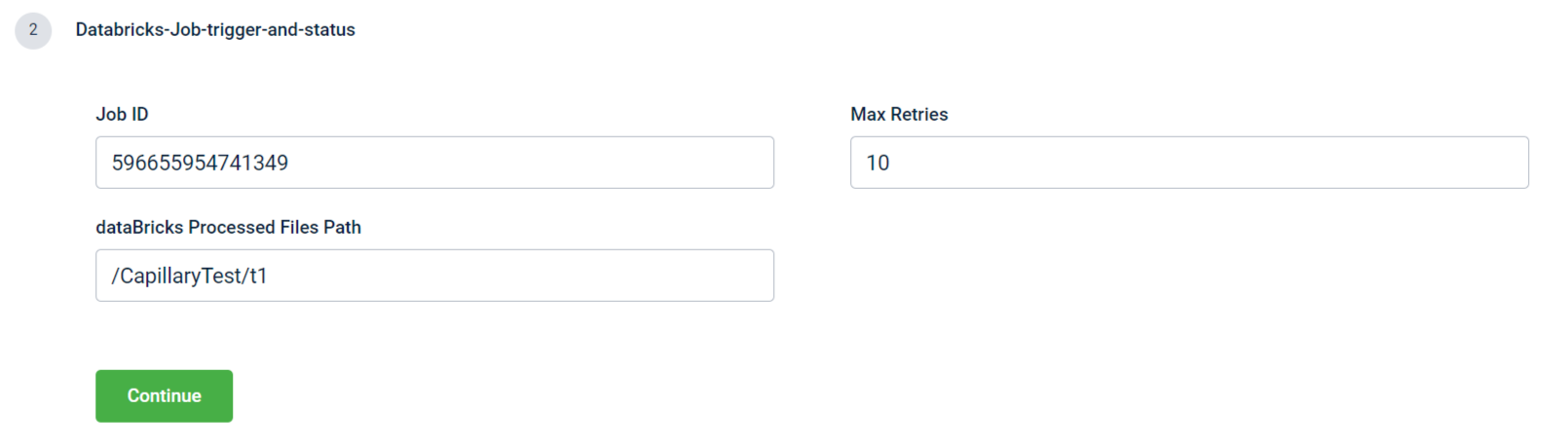
In the Databricks-Job-trigger-and-status block, enter the following information:
-
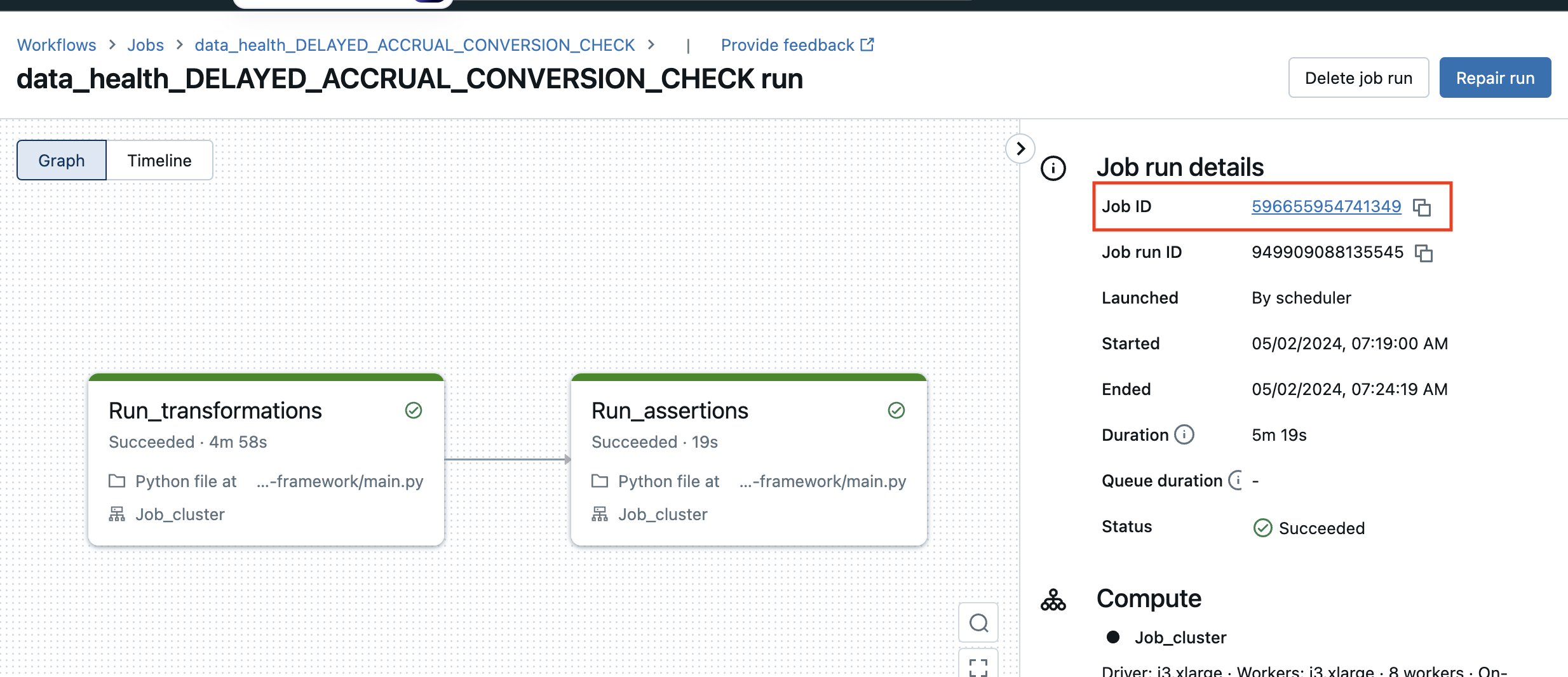
Job ID: Enter the jo ID of the Databricks job that needs to be triggered.
-
Max retries: This parameter defines the maximum number of attempts a file undergoes processing before it is marked as failed. By default, the maximum retries value is set to 10. When a Databricks job is triggered, and while it is running, subsequent job triggers must wait until the ongoing job completes. The system periodically checks the status of the job every minute until either the job completes successfully or reaches the maximum retry count. If the job is still running after one minute, the system enters a retry loop, continuously checking the job status until it either completes or until the maximum retry count is reached. If the maximum retry count is exceeded without successful completion, the file in the queue is considered unprocessed.
-
dataBricks Processed Files Path: This parameter specifies the destination file path where Databricks stores the files after executing the job. Regardless of whether the job succeeds or fails, the resulting files are stored at this location. The Databricks uses the credentials entered in the "Connect to source" section to add the files to this location.
-
- In the Trigger block, enter the details to schedule the trigger. See Trigger.
For troubleshooting information, refer to the troubleshooting section of the documentation.
Updated 7 months ago