
Ingest Kafka Stream in API
This template imports data from the Kafka queue into the Capillary system and then transforms it for further processing.
Use case
Scenario
An airline brand uses a Passenger Service System (PSS) to send post-flight passenger data to the Capillary platform. The data includes details like passenger information, flight completion status, and other relevant metadata. This data is sent in bulk every hour, reaching up to 1,000 requests per minute. Due to the high volume and frequency, the PSS streams this data into a Kafka queue.
The system needs a reliable and scalable way to:
- Continuously consume data from the Kafka queue
- Transform it into a format that Capillary’s platform can process
- Forward the processed data for downstream use, such as awarding loyalty points or updating customer profiles
Solution
Use the "Ingest from Kafka Stream" template in Connect+ to build a Kafka consumer that retrieves and processes data efficiently.
This setup will:
- Connect to the specified Kafka topic using OAuth-based credentials
- Consume messages in real time as they arrive in the Kafka queue
- Transform the incoming payloads using a JavaScript-based transformer to match Capillary's expected schema
- Forward the transformed data to the appropriate platform APIs for processing (e.g., behavioral event ingestion, customer updates)
Prerequisites
The following are the prerequisites for using the Ingest Kafka Stream in API:
- Name of the Kafka server
- Kafka topic
- Consumer group ID
- Username and password to access the Kafka server.
Configuring Ingest Kafka stream in API
Below is a screenshot of the template, showing the various blocks.
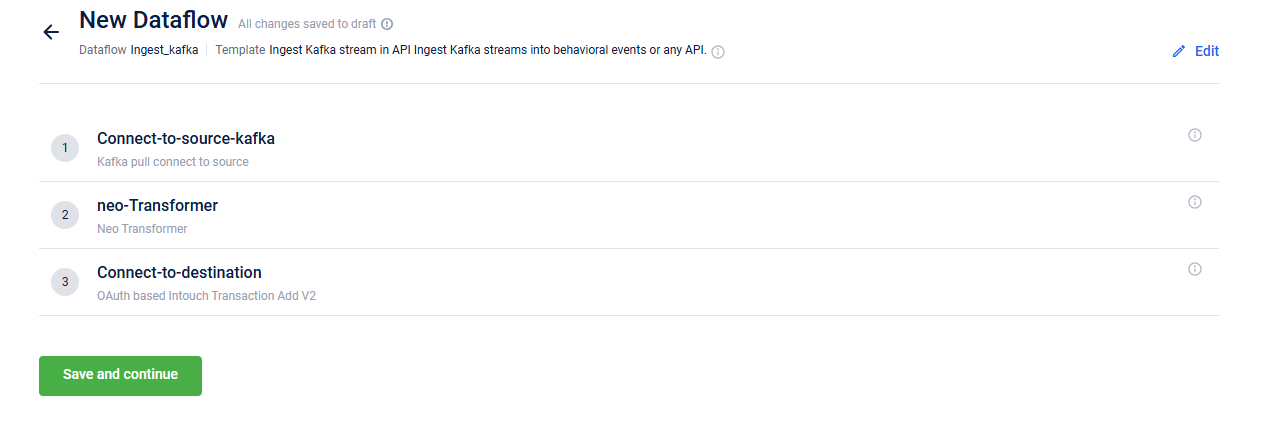
To configure Ingest Kafka stream in API template, the following are the steps:
- In the Connect-to-source-kafka block, enter the Kafka details, including the server address, Kafka topic, username, and password from where the events are imported. For the information on configuring this block, refer to Connect-to-source-kafka.
- In the neo-Transformer block, enter the URL of the Neo dataflow created to transform the data required as per your requirement. For the information on configuring this block, refer to neo-Transformer.
- In the Connect-to-destination enter the details of the API endpoint. For the information on configuring this block, refer to Connect to destination.
Connect-to-source-kafka
This block enables you to define the Kafka server details. Below is the screenshot showing the fields in the block.
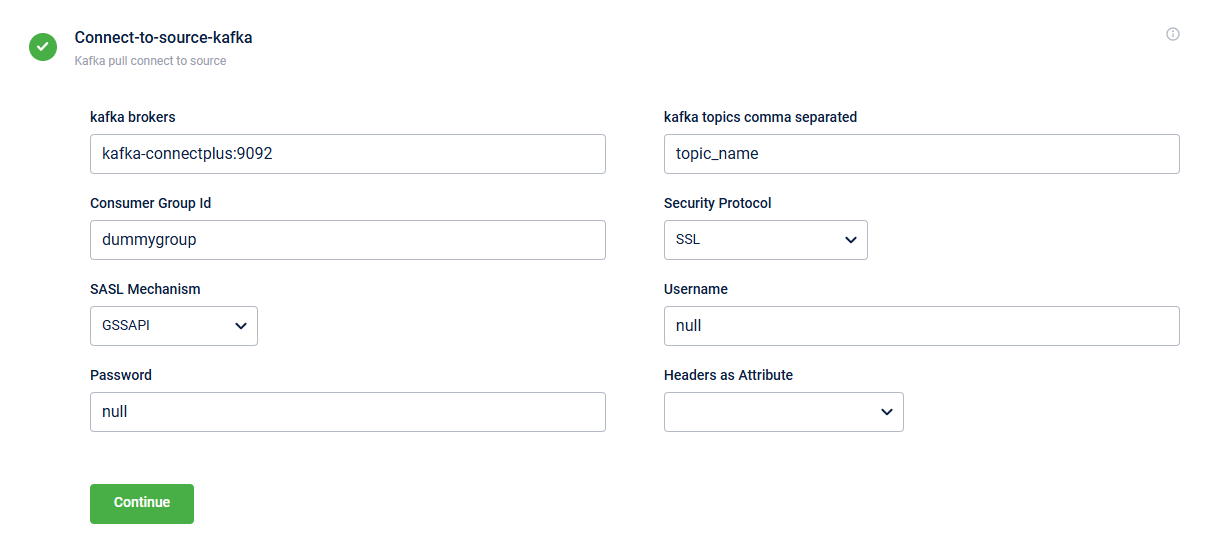
The table below describes the fields in the block:
| Field Name | Description |
|---|---|
| kafka brokers | Kafka server URL. The URL is a combination of the server address and the port number.
|
| kafka topics | Predefined topic name from which you consume messages. These topics must already exist in your Kafka system. You can list multiple topics separated by commas. It is not recommended to use the same Kafka topics for multiple dataflows. |
| Consumer Group Id | Specifies the predefined consumer group ID used for access control. |
| Security Protocol | Specify the security protocol you want to use to exchange data between the Kafka client and server. The supported protocols are:
|
| SASL Mechanism | Specify the authentication method used to connect to Kafka. The supported mechanisms are:
|
| Username and Password | Username and password to access the Kafka server. |
| Headers as Attribute | Headers from the Kafka message contain metadata like user-id, priority, and source-system. These headers are extracted as data attributes and are available for all the steps in Connect+. The headers are required for the following:
|
neo-Transformer
The Neo Transformer block allows you to call a NEO dataflow for data transformation. Below is the screenshot showing the fields in the block.
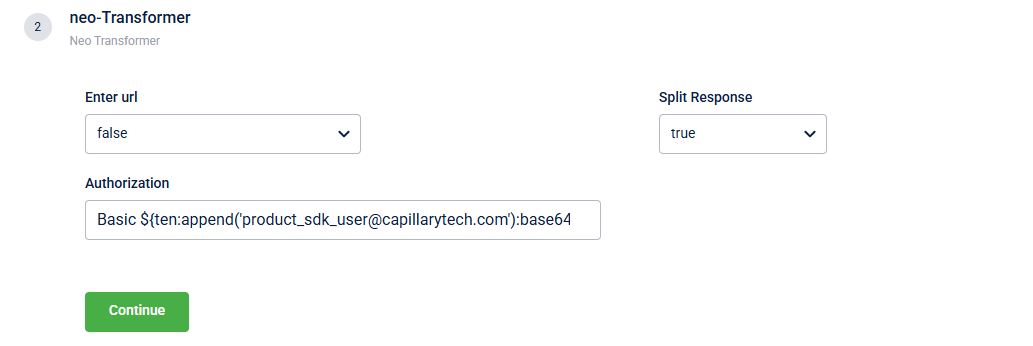
The table below describes the fields in the block.
| Field Name | Description |
|---|---|
| Enter url | Select the from the drop-down menu. The drop-down lists Dataflows with the |
| Authorization | Authorisation key for the API (if required). |
| Split Response | Splits the response when the API returns an array of objects.
|
Updated 5 months ago